Módszertan
 English
English |
 Deutsch
Deutsch |
 Súgó
Súgó |
 Belépés
Belépés |
|
|
Módszertan |
|
|
|
|
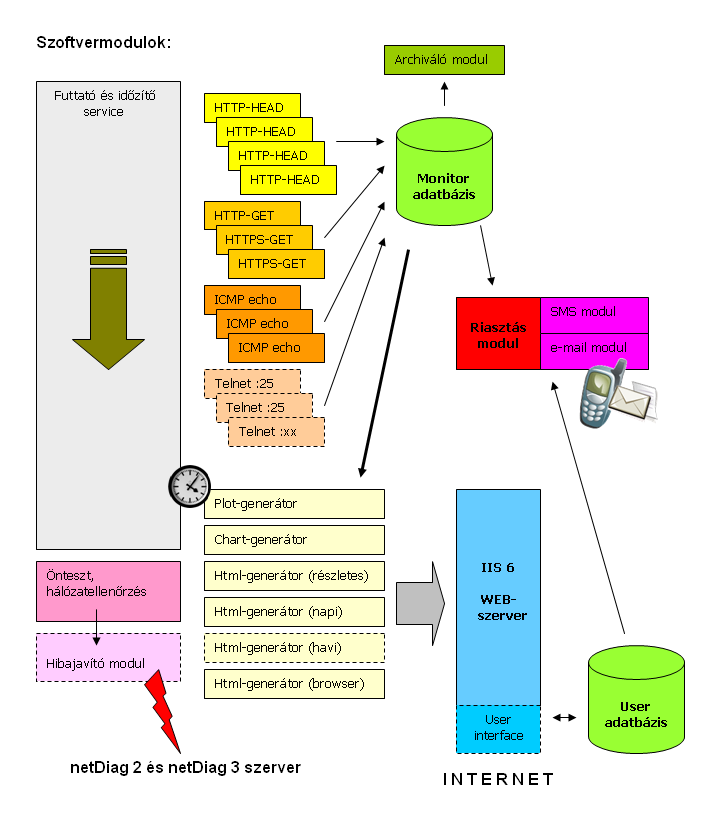
A netDiag szolgáltatás hardveres háttereA monitorozást jelenleg három dedikált szerver végzi párhuzamosan. A szerverek BIX-hez közeli
termekben vannak elhelyezve (T-Online Adatpark, Dataland,
Invitel),
de a későbbiekben tervezzük, hogy a BIX-től fizikailag és
adatkapcsolatilag távolabbi helyekre is telepítsünk gépeket. A szerverek
természetesen megbízható szünetmentes tápellátással és stabil 100
Mbps-os hálózati kapcsolattal rendelkeznek.
A netDiag szolgáltatás szoftveres háttereA különféle típusú adatgyűjtések, a risztás és a web-oldalak generálása multitaskos és multithreades programmodulokkal történik, a modulok futását egy független felügye- leti modul ellenőrzi. A szerverek szigorú időszinkronban dolgoznak (naponta történő újraszinkronozással), így a monitorlogok szükség esetén egyszerűen összefésülhetők. A szervereken egyforma szoftverkörnyezet fut, a monitorozás normál esetben párhuzamosan két helyről történik, az elsődleges szerver kiesésekor a másodlagos tovább gyűjti az adatokat ill. kiküldi a riasztásokat is, tehát a web-felület kivételével a többi funkció tovább él. A hatékonyság növelése érdekében majdnem minden megjelenítendő adatot előre legenerálunk, így az időigényes (sql-lekérdezésekkel tűzdelt) szerver oldali scriptek száma minimálisra csökkenthető, gyakorlatilag a user interfacere korlátozódik. A web-lekérdezésekhez a Microsoft által az IE6-hoz kifejlesztett WinHTTP 5.1 API-t használjuk.
Hogyan történik a monitorozás?Jelenleg az ICMP echo request (Ping) és a HTTP(s) protokoll GET és a HEAD metódusait használjuk, de teszteljük a HTTP(s) POST-ot és a Telnetet is, ez utóbbi pl. SMTP szerverek ellenőrzésekor hasznos.
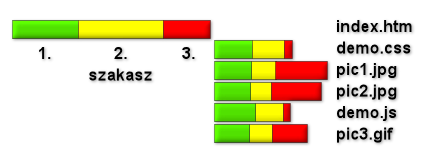
A HTTP lekérések/válaszok az időtengelyen első közelítésben három jól elkülöníthető szakaszra bonthatóak: az első szakasz a kapcsolat felépítése (connect), a második a szerver felkészülése a válaszadásra (a dinamikusan generált html oldalak összeállítása a legtöbb esetben bufferelt, ezért ez a szakasz szerveroldali scriptek futtatása esetén (főként akkor, ha adatbázis-lekérdezések is történnek) elég hosszú (3-5 másodperces) is lehet), végezetül a harmadik szakasz, a válasz letöltésének az ideje az elsőtől az utolsó bájtig (ez nagyban függ a letöltendő tartalom hosszától és a hálózat sebességétől). Mi a fentiek közül -- néhány kényszerű, vagy megrendelői igény szerinti kivételtől eltekintve -- csak az első kettőt vizsgáljuk (a hálózat és a szerver "egészségi állapotára" ezekből elég jól következtethetünk), így ahol lehet, a HEAD metódust használjuk (ez végrehajtásában lényegében megegyezik a GET-tel, viszont az üzenettestet nem adja vissza, ezáltal nem generálunk felesleges adatforgalmat, és a harmadik szakasz idejét is jelentősen lecsökkenthetjük).
A fenti három szakasz természetesen csak egyetlen letöltött adattartalmat reprezentál (a mi esetünkben ez általában a vizsgálandó webmappa index.htm-e (vagy valamilyen dinamikusan generált php, asp oldala), valójában a komplett html-oldalakhoz számos egyéb objektum is tartozik (képek, css stíluslapok, scritpfájlok, flash-animációk stb.). Mivel célul a szerverek működésvizsgálatát és nem a "felhasználói élmény" mérését tűztük ki, ezen tartalmakkal nem foglalkozunk. Annál is inkább, mert egyrészt az URL-lel hivatkozott html fájl betöltése után a böngészők több (az IE6 default pl. 10) szálon kezdik el letölteni a kapcsolódó objektumokat, másrészt elképzelhető, hogy ezen objektumokból néhány egy másik szerveren van (pl. független web-audit céljából).
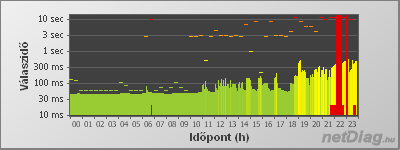
A monitorozás beállítástól függően 1-2-3-5 percenként történhet (minden egyes URL-re külön-külön beállítható), a monitorozott adatok (mint a monitorozás típusa, id-je, válaszideje és esetlegesen hibakódja) bekerülnek egy adatbázisba. A mért adatok közvetlenül is megtekinthetőek a napi elérhetőségi statisztikák oldalán, az óra értékekre kattintva. A könnyebb vizuális kiértékelhetőség érdekében idődiagramok (=plotok) is készülnek, ezeken egy speciális csúszó átlagolás simítja ki a kisebb ugrásokat, így jobban láthatóak a tendenciák. Az ötperces maximumértékeket és az egyszeri valamint ismétlődő hibákat szintén feltünteti a plot (lásd részletesebben a súgóban).
A riasztás funkció
A netDiag rendszer alapvetően három esetet különböztet meg monitorozáskor:
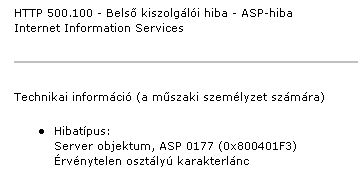
Ez utóbbi két esetet megkülönböztetjük egymástól, de egyformán hibának tekintjük. (Megjegyzés: hamarosan a normál válasz kiegészíthető még egy string-ellenőrzéssel is, ez akkor hasznos, ha a szerver látszólag válaszol, a válasz viszont hibás (pl. PHP, ASP vagy SQL hiba miatt). )
A timeout időket önkényesen határoztuk meg, figyelembe véve a böngészés ergonómiájával foglalkozó tanulmányok megállapításait is:
Ha a fenti három timeout idő bármelyikét elérjük monitorozáskor, akkor az adott lekérdezést hibásnak tekintjük. Előfordulhat tehát, hogy a vizsgált szerver 11 másodperc után válaszolna, de ezt (hangsúlyozzuk ismét: érthető és ésszerű okokból, de teljesen önkényes módon) elfogadhatatlanul hosszú időnek tartjuk.
A hibák előfordulása lehet egyszeri (ide soroljuk az egymás után legfeljebb 3-4 alkalommal ismétlődő hibákat is) ill. folyamatos. Egyszeri hiba szinte bármilyen jólműködő rendszernél előfordulhat, nemcsak szolgáltatói oldalon, de az adatkapcsolati lánc bármely pontján, tehát ez a fajta hiba a monitorozás szempontjából szinte lényegtelen. Más a helyzet az ismétlődő, folyamatos hibákkal: ezek általában súlyosabb (időnként fatális) problémák következményei (hardveres meghibásodás, hosszú áramszünet, súlyos szoftverhiba, jelentős hálózati kimaradás, hackertámadás stb.) Az is előfordulhat, hogy a válaszidők megnőnek és gyakorivá válnak a timeoutok: ez arra figyelmeztet, hogy a monitorozott szerver (pontosabban rendszer, mert nem feltétlenül egy szerver) teljesítőképessége határán van. Ilyenkor nem kell azonnal új vasért rohanni, hiszen időnként a meglévő szoftver optimalizálása, az adatbázis-lekérdezések újragondolása is csodákat tehet.
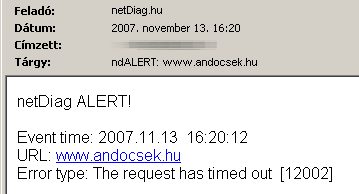
A folyamatosan, perceken keresztül fennálló, automatikusan nem javuló hibák általában humán beavatkozást igényelnek: az esetek egy részében elegendő a távoli belépés, de néha elkerülhetetlen az operátori beavatkozás vagy a helyszíni javítás. A legtöbb webes alkalmazásnál igény van a hiba mielőbbi felfedezésére és elhárítására, hiszen a "döglött" weboldal amellett, hogy nem termel hasznot, meglehetősen imázsromboló is tud lenni. Erre szolgál a netDiag riasztás funkciója, amely konkrétan e-mail vagy SMS küldés lehet, egyszerre akár több címre ill. telefonszámra is. Mind az e-mailben, mind az SMS-ben feltüntetjük a riasztás időpontját (Figyelem! Mivel a riasztás feltétele a folyamatosan (a felhasználó által beállítható 5-10-15 percen keresztül) monitorozott hiba, így a riasztás időpontja nem esik egybe a szerver leállásának időpontjával.), a szerver URL-jét és a hiba rövid leírását. A riasztás kiküldése után (szintén a felhasználó által meghatározható ideig, praktikusan általában 1-2 óráig) nem küldünk ki újabbat, hiszen annak nem sok értelme lenne. Ha a hiba nem hárul el, a várakozási idő lejárta után SEM küldünk ki újabb riasztást, csak akkor, ha a szerver ismét dolgozni kezd, majd ismét legalább 5-10-15 percre leáll. Az SMS-nél emellett beállítható "silent alert" időszak is, ilyenkor SMS nem kerül kiküldésre (ez pl. olyankor hasznos, amikor a cégvezető napközben értesülni szeretne a leállásokról, éjszaka viszont inkább aludna...).
A netDiag rendszer az összes riasztást naplózza, így a megfelelő működés bármikor visszamenőlegesen is ellenőrizhető. Az SMS-ek kiküldését szükség esetén a mobilszolgáltatótól kapott havi részletes listákkal is tudjuk igazolni.
|
|
|
|
|





{kind=link}
{kind=link}